做一下记录。
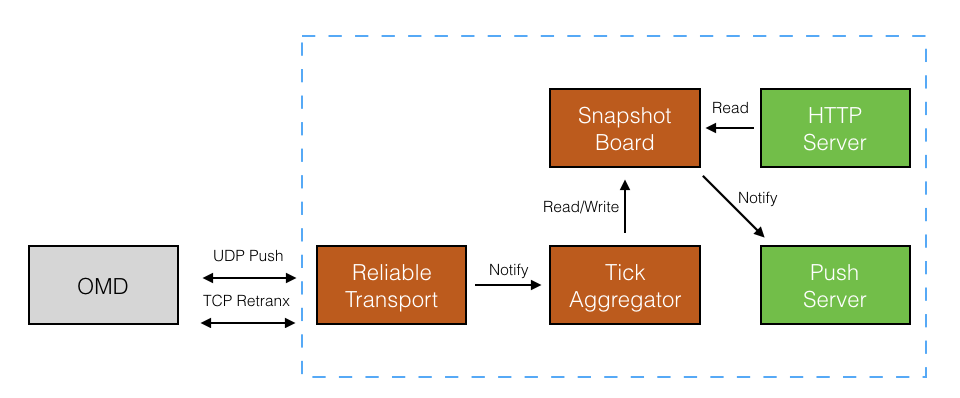
做了一个可靠传输层,优点是层次分明,缺点是当丢包时价格更新不及时。可以优化成只重传不排序,Aggregator 区分是否是最新包,不是最新包则不更新最新价。
对外提供推和拉接口,两种都有适用场景,不能只提供一种。Query Server 采用 HTTP 协议,Push Server 可以用 WebSocket 协议。
把图改成 stack 形式。
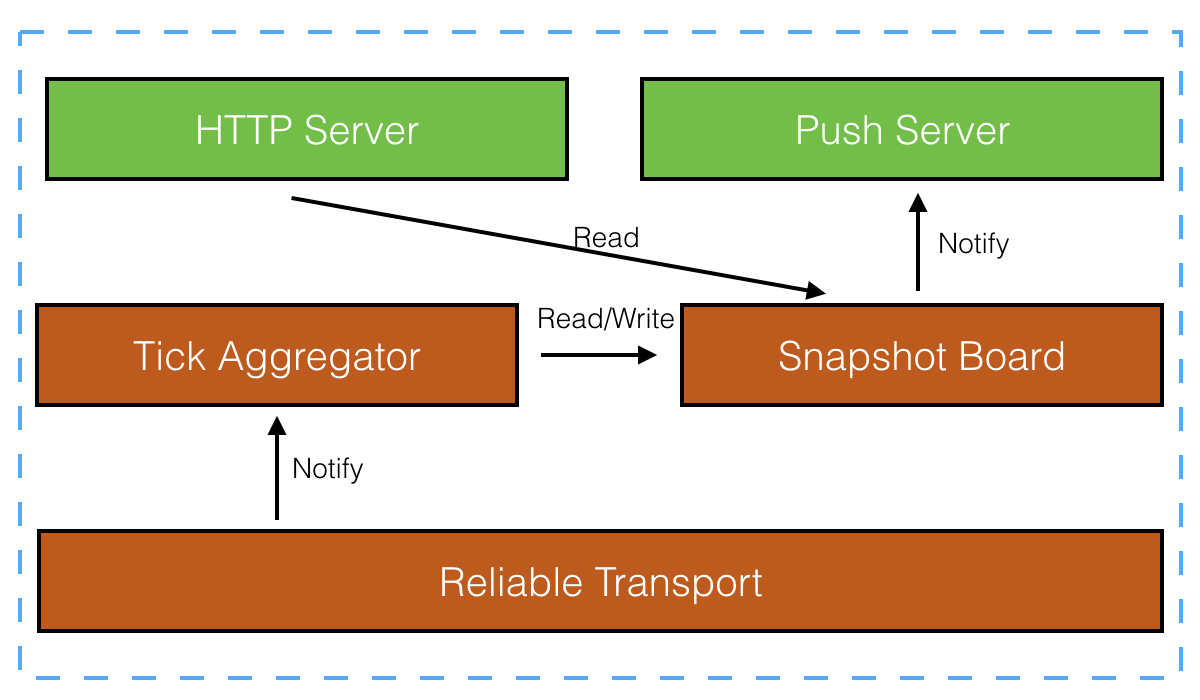
做一下记录。
做了一个可靠传输层,优点是层次分明,缺点是当丢包时价格更新不及时。可以优化成只重传不排序,Aggregator 区分是否是最新包,不是最新包则不更新最新价。
对外提供推和拉接口,两种都有适用场景,不能只提供一种。Query Server 采用 HTTP 协议,Push Server 可以用 WebSocket 协议。
把图改成 stack 形式。
直播,电话通话,视频聊天都是实时流媒体的范畴。无论使用 TCP 还是 UDP,都会有延时。有个过时的观点是 UDP 更实时,但我不认为是这样。
实时流媒体的延时主要有几个因素:发送方缓冲,接收方缓冲,网络延时。缓冲包括网络缓冲,录制缓和冲播放缓冲。假设发送方缓冲是 10ms,接收方缓冲都是 50ms,网络延时是 100ms,那么就有至少 160ms 的播放延时。接收方缓冲比发送方多,是为了解决所谓的 jitter,网络延时不均匀导致的播放断续。
如果使用 UDP,如果丢包,那么接收方的缓冲就从 50ms 变为 40ms,交互延时变小,随着继续丢包变为 0 时,网络延时不旦不均匀就会发生 jitter 了。这时开始缓冲,一共花 50ms,所以信号中断最多 50ms,也即接收方缓冲。
如果使用 TCP,丢包会导致 TCP 重传,因为网络 rtt 是 200ms,到 50ms 时,接收方的缓冲已经没有数据了,只能等待网络传输,然后再等 150 ms(也即信号中断 150 ms),突然一次收到 110ms 的数据到接收方缓冲中。为了保证低延时,主动丢弃最早的 60ms 数据。使用 TCP,信号中断时时长是 150 ms,也即网络 rtt 减去接收方缓冲。因为 TCP 最坏情况要重传3次,所以是 3*rtt 减去接收方缓冲。
运行于 UDP 之上的 SIP,因为 UDP 是不可靠传输的,所以 SIP 协议本身要自己实现可靠传输。对于如何可靠传输,SIP 的 RFC 文档没有要求实现独立的传输层,而是将可靠传输融合进交互过程本身。如果像 TCP/IP 协议那样分层,特点是清晰。而将可靠传输隐含于交互,则可控程度更高,当然也更复杂。
所以,RFC 中创造了一些概念,如 Transaction 等等,对于有经验的程序员来说,这完全没必要,反而造成困扰。对于程序员,用几句简单的过程描述就可以解决。如下。
Client: 定期重复发送 INVITE 直到收到响应。
Server:收到 INVITE 后,定期重复发送响应,直到收到 ACK。
Client:收到响应后回复 ACK,认为会话已经建立。这时如果再次收到响应,回复一个 ACK。
Server:收到 ACK,认为会话已经建立。这时如果再次收到 INVITE 或者 ACK,丢弃。
SIP 的一次通话,可以通过 From, To, Call-ID 三元组来区分。但是,为什么 From 和 To 不用固定的地址,而要在地址后面加上 tag=随机数 呢?
tag 的目的是为了解决自己给自己打电话的问题(Hairpinning)。如果你自己给自己打电话,那么你应该有两个 Session,但是,如果 From 和 To 是固定的,你就无法区别这两个 Session 哪个是 caller 哪个是 callee。发送 INVITE 时,caller 会在 From 中带有 tag=随机数,而 callee 发送响应时,在 To 后面补充 tag=随机数,不同的随机数分别表示 caller 和 callee。
所以,RFC 3261 中说:
The combination of the To tag, From tag, and Call-ID completely defines a peer-to-peer SIP relationship...
用的是 From tag 和 To tag,而不是用 From 和 To。
Via 是网络层的信息,SIP 报文将通过网络层发往这两个地址。Contact 是业务上的地址。那么问题是,应该发往哪个?
正确的做法是,请求响应模式中的响应发往 Via。如果解析 DNS 之后能直连 Contact,那么之后的报文(无论是否是请求响应模式)发往 Contact。
请求如果经过多个代理,每个代理都增加自己的 Via,变成 Via 列表。最终节点回复响应时,带有全部 Via 列表,根据最后一个 Via 获知要发送的目的网络地址。每个代理转发响应时,把最后一个属于自己的 Via 删除,再根据前一个 Via 得到要转发的目的网络地址。
这样,代理可以做无状态转发请求和响应,其中请求转发依赖路由表,响应转发依赖 Via 列表。
面试了很多做了多年网络编程的人, 从TCP socket中读取报文这项基本技能, 许多人都做不对. 经典的错误用法是:
char buf[1024]; // 1024或者更大
read(sock, buf, sizeof(buf));
if(parse(buf) == 1){
// 报文解析完毕
}else{
// 不是一个完整的报文, 丢弃
}
这是非常经典的错误! 没有任何文档或者手册表明, read()会读到*完整*的报文, 对于read()函数来说, 它只知道字节流, 不知"报文"为何物. read()可能只读到了1个字节的数据就返回... 而且, read()返回的数据的长度, 和对方write()不是一一对应的. 对方调用1次write(), 可能本方要调用1次或者2次或者更多次read().
这个错误之所以经典, 是因为在局域网条件下, 且报文非常小的情况下, 一般(仅仅是一般, 不是100%)write()和read()是一一对应的, 所以, 有些人即使是在BAT公司写了10年网络编程, 也发现不了这个错误. 这个错误就是所谓的"TCP粘包/断包".
看看这个PDF: 高性能并发网络服务器设计与实现.pdf, 看看如何正确地从TCP socket中读取报文. 或者看看 Sim C++ 框架的源码, 了解下 Sim 是如何从 TCP socket 中读取一个报文: https://github.com/ideawu/sim/blob/master/src/server.cpp#L143

|
带有此标志, 表示本博客已经被加入到IT牛人博客聚合网站. |